Creativity has always been the essence of human evolution. For thousands of years, humans have unearthed many wonderful discoveries in the long river of history, and the origin of this behavior may be the first wheel rolling, or the spark of thinking behind a crazy idea. From the Stone Age to today, creativity has always been appreciated, and it has indeed brought us a steady stream of motivation for progress.
Nowadays, various fields are enriching the connotation of creativity. Among them, data science should be one of the most welcome fields: from null hypotheses, data preprocessing, and building models—creative insights play an important role in it.

Photography: Franki Chamaki
A Kaggle master once said to me:
The more you solve the problem, the deeper your understanding of certain ideas and challenges, and you will find that certain things will work wonders for certain problems.
In competition practice, this experience is particularly evident in feature engineering. The so-called feature engineering refers to the process of extracting features containing a large amount of information from data to facilitate the easy learning of the model.
Why is feature engineering so important?
Many beginners in data science are now "superstitious" LGBM and XGBoost, because they are really effective and accurate. Correspondingly, the traditional linear regression and KNN began to fade out of people's field of vision.
But in some cases, the effect of linear regression is not necessarily worse than GBM tree, and sometimes even better. Taking my personal experience as an example, the linear regression model has helped me gain an advantage in many competitions.
The statistician George Bock has a saying that is regarded as a standard by many statistics practitioners:
All models are wrong, but some of them are useful.
This means that the model is only powerful when it finds certain features that have a significant relationship with the target variable. And this is where feature engineering comes into play-we design and create new features so that the model can extract important correlations from them.
Before I participated in a DataHack competition, the content is to use a data set to predict power consumption. Through heat maps and exploratory data analysis, I drew the following picture:
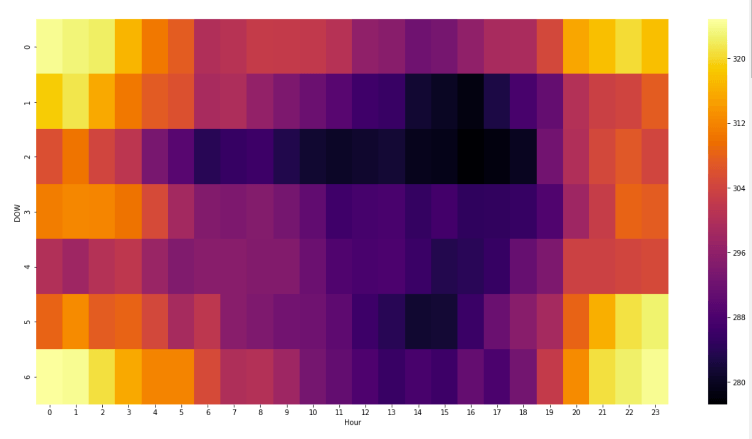
The ordinate DOW of the heat map represents 7 days a week, and the abscissa is 24 hours a day. Obviously, the electricity usage throughout the weekend is very similar to the electricity usage late at night during the working day. From this, I created a feature-weekend proximity, which not only improved the model score, but also helped me eventually win the competition.
Therefore, it is very important to make good use of creativity in machine learning competitions. Here are a few well-known but not commonly used feature engineering techniques, some of which are somewhat sidetracked:
Convert data into images
Meta-leaks
Representation learning features
Mean coding
Conversion target variable
Convert data into images
There is a Microsoft malware classification challenge on Kaggle. Its data set contains a set of known malware files. For each file, the original data contains the hexadecimal representation of the binary content of the file. Previously, the contestants had never been exposed to similar data sets on the Internet, and their goal was to develop the optimal classification algorithm and put the files in the test set into their respective categories.
At the end of the competition, "say NOOOOO to overfittttting" won the first place. Their magic weapon is to use the image representation of the original data as a feature.
We regard the byte file of the malicious file as a black and white image, where the pixel intensity of each byte is between 0-255. However, standard image processing techniques are not compatible with other features such as n-grams. So afterwards, we extract the black and white image from the asm file instead of the byte file.
The following figure is a comparison of byte images and asm images of the same malware:

Byte image (left) asm image (right)
The asm file is a source program file written in assembly language. The team found that after converting the asm file into an image, the pixel intensity of the first 800-1000 pixels of the image can be used as a reliable feature for classifying malware.
Although they said they didn't know why this would work, because using this feature alone will not bring significant changes to the classifier performance, but when it is used with other n-gram features, the performance improvement effect is very significant.
Convert the original data into an image, and use pixels as features. This is one of the amazing feature projects that appeared in the Kaggle competition.
Metadata breach
When the processed features can perfectly explain the target without applying any machine learning, a data leak may occur.
A recent Kaggle competition, the Santander Customer Value Prediction Challenge, had a data leak. Participants only need to do a brute force search on the sequence of rows and columns, and finally they can explain their goals well.

Santander's data breach
As shown in the figure above, the target variable is obviously leaked into the f190486 column. In fact, I got 0.57 points without using any machine learning, which is a high score on the leaderboard. About twenty days before the deadline of the competition, Santander Bank, which hosted the competition, finally discovered the problem, but they finally decided to continue the competition and let the participants assume that this was a data attribute.
Although this kind of error is very rare, if you just want to get a good ranking in the competition, you can try to extract patterns from features such as file name, image metadata, and serial number at the beginning. Please note that this approach by itself has no effect on actual data science problems.
Compared to spending a lot of time on IDA and other features, if you really do exploratory data analysis (EDA) every time, you may find a "shortcut" to the competition.
Representation learning features
For the older data science contestants, they must be very familiar with basic feature engineering skills, such as Label Encoding, one-hot encoding, Binning, and so on. However, these methods are very common, and now everyone knows how to use them.
In order to stand out from the crowd, in order to occupy a higher position on the leaderboard, we need to discover some clever methods, such as autoencoders. The autoencoder can perform unsupervised learning from data samples, which means that the algorithm captures the most salient features directly from the training data without other feature engineering.
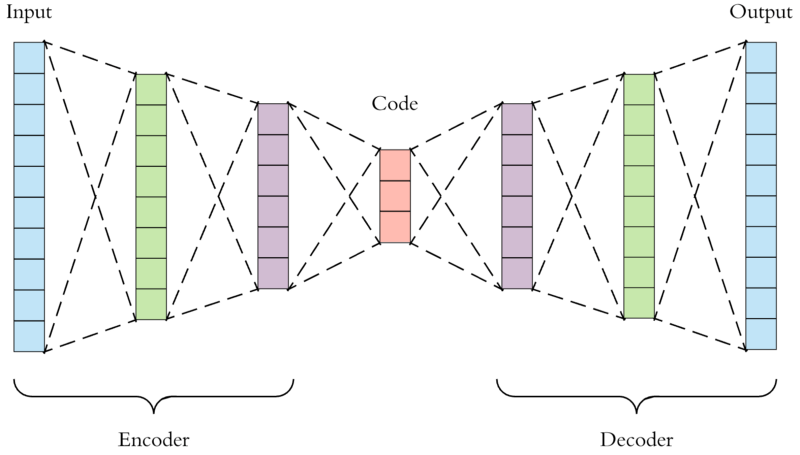
Autoencoder
The autoencoder is just given a representation learning model, it learns the input, and then generates the input itself. Example: This is like showing a person an image of a cat, and then asking him to draw the cat he saw after a period of time.
Intuition is the best observation feature extracted during the learning process. In the above example, humans will definitely draw two eyes, triangular ears and beards. Then the following model will use these intuitions as an important basis for classification.
Mean coding
Mean coding is actually very common. This is a very suitable technique for beginners, which can provide higher accuracy while solving problems. If we replace the classification value with the target value in the training data, this is called Target Encoding; if we use a statistical measure such as the average to encode the classification value, this is called Mean Encoding.
The following is an example. We need to encode tags based on the value_counts of each type of target variable, through the number of tags and the target variable.
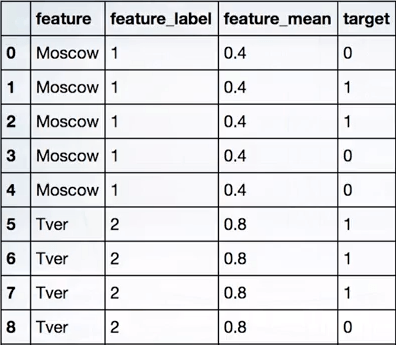
Among them, featurelabel is a label coded by scikit-learn, and featuremean is the number of real targets under the Moscow label/the total number of targets under the Moscow label, which is 2/5=0.4.
In the same way, for the Tver tag——
m=the number of real targets under the Tver label=3
n=Total number of targets under the Tver label=4
Correspondingly, the Tver code is m/n=3/4=0.75 (approximately equal to 0.8)
Q: Why is mean coding better than other coding methods? Answer: If the data has high cardinality category attributes, then the mean value coding is a simpler and more efficient solution than other coding methods.
In data analysis, category attributes are often encountered, such as date, gender, block number, IP address, etc. Most data analysis algorithms cannot directly deal with such variables, and they need to be processed into numerical quantities first. If the possible values ​​of these variables are few, we can use conventional one-hot encoding and label encoding.
However, if the possible values ​​of these variables are many, that is, high cardinality, then in this case, using label encoding will result in a series of continuous numbers (within the cardinality range), and adding noise labels and encoding to the features will lead to poor accuracy . And if one-hot encoding is used, as features continue to increase, the dimensionality of the data set is also increasing, which will hinder encoding.
Therefore, mean coding is one of the best choices at this time. But it also has a disadvantage, that is, it is easy to overfit (provide a lot of data), so it should be used with appropriate regularization techniques.
Regularization with CV loop tool
Regularization Smoothing
Regularization Expanding mean
Conversion target variable
Strictly speaking, this is not a feature engineering. However, when we get a highly skewed data, if we do not do any processing, the performance of the final model will definitely be affected.
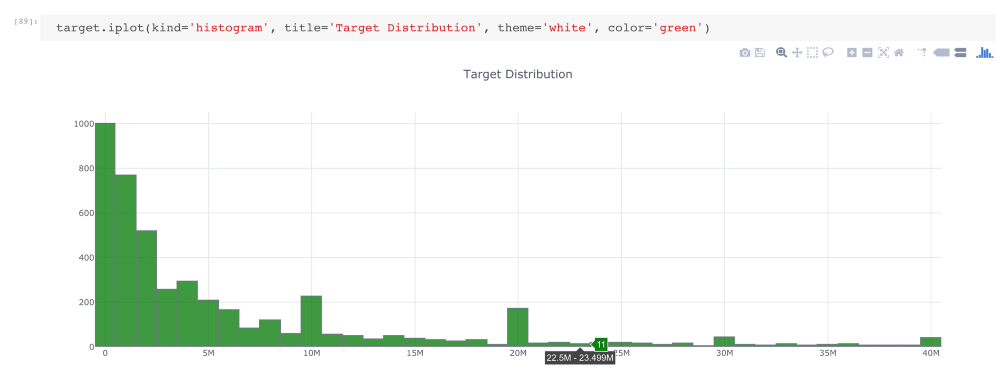
Target distribution
As shown in the figure above, the data here is highly skewed. If we convert the target variable to log (1+target) format, then its distribution is close to Gaussian distribution.
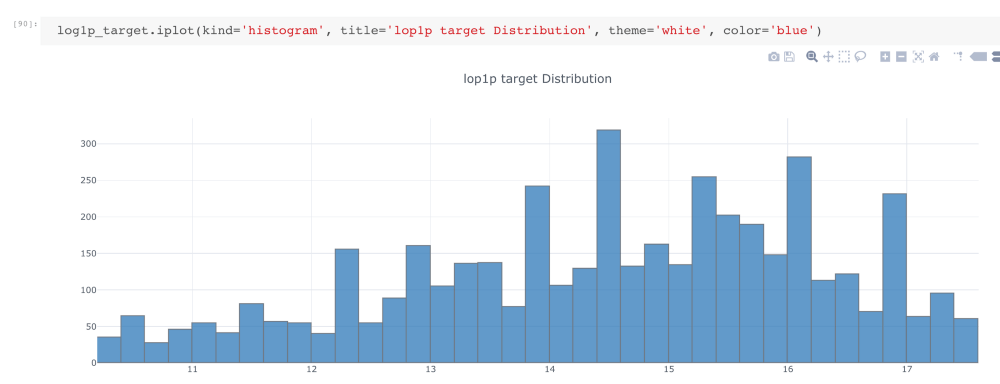
It should be noted that when submitting predictions, we need to convert: predictions = np.exmp1(log_predictions).
The above is my experience, I hope this article is helpful to you!
Nickel Alkaline Battery,Solar Energy Battery,48V Nife Battery 200Ah ,Ni-Fe Battery 100~200Ah
Henan Xintaihang Power Source Co.,Ltd , https://www.taihangbattery.com