Top10 algorithm for machine learning
In the field of machine learning, there is no omnipotent algorithm that can solve all problems perfectly, especially in supervised learning like predictive modeling.
For example, neural networks are not necessarily better than decision trees, and vice versa. The end result is that there are many factors at work, such as the size and composition of the data set. So, for the problem you are trying to solve, it is best to try a variety of different algorithms. And use a test set to evaluate the performance between different algorithms, and finally choose the best one.
Of course, you have to choose an algorithm that is suitable for solving your problem. For example, to clean the house, you will use a vacuum cleaner, a broom, a mop; you will never flip a shovel to start digging, right. However, there are some general underlying principles for all predictive modeling supervised learning algorithms.
Machine learning algorithms refer to learning an objective function that restores the relationship between input and output as much as possible.
The output value Y is then predicted based on the new input value X. Precisely predicting results is the task of machine learning modeling.
So let's take a look at Top10 machine learning algorithm 1 linear regression
The most studied algorithm in the field of statistics and machine learning. For predictive modeling, the most important is accuracy (minimizing the error between predicted and actual values). Even if sacrifices are interpretable, try to be as accurate as possible. In order to achieve this, we will refer to or copy the algorithm from different fields (including statistics). Linear regression can use a line to represent the relationship between the input value X and the output value Y. The value of the slope of this line is also called the coefficient.
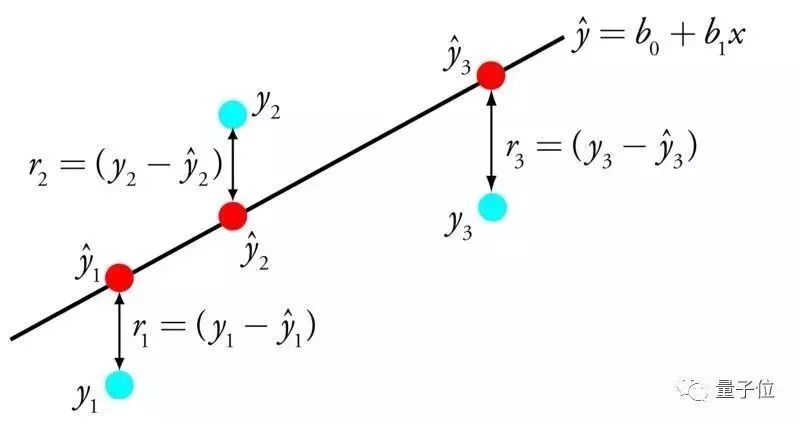
For example, y = B0 + B1*x, we can predict the Y value based on the X value. The task of machine learning is to find the coefficients B0 and B1. There are different methods for establishing linear regression models from data, such as least squares of linear algebra and gradient descent optimization. Linear regression has existed for more than 200 years, and there have been many related researches. The key to using this algorithm is to remove similar variables and clean the data as much as possible. For the algorithm new, it is the simplest algorithm.
2 logistic regression
This method comes from the field of statistics and is a method that can be used on binary classification problems. Logistic regression, similar to linear regression, is to find the coefficient weight of the input value. The difference is that the prediction of the output value is changed to a logical function. The logic function looks like the letter S, and the output value ranges from 0 to 1. By adding a processing rule to the output value of the logic function, the classification result can be obtained, which is not 0 or 1. For example, you can specify that the input value is less than 0.5, then the output value is 1.
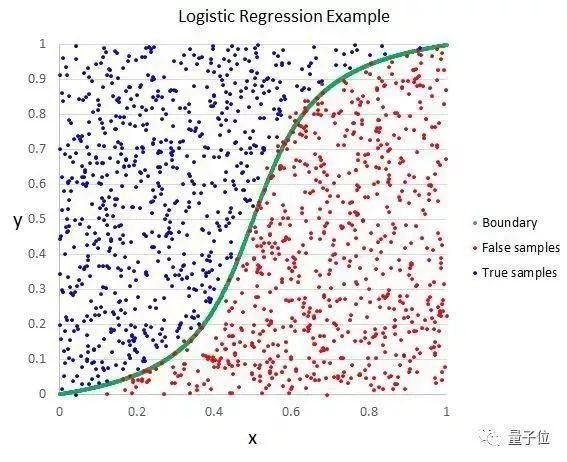
This algorithm can also be used to predict the probability of data distribution and is suitable for predictions that require more data justification support. Similar to linear regression, the logistic regression algorithm performs better if the output-related factors or similar factors are eliminated. For the binary classification problem, logistic regression is a fast and effective algorithm.
3 linear discriminant analysis
Logistic regression algorithm can only be used for binary problems. When the output result category exceeds two categories, the linear discriminant analysis algorithm is used. The visualization results of this algorithm are also relatively clear, and the statistical characteristics of the data can be seen. The above results are calculated separately. The single input value can be the median of each class or the span of each type of value.
The prediction is made by taking the maximum value based on the discriminant value obtained after each category is calculated. This method assumes that the data conforms to a Gaussian distribution. Therefore, it is best to kick out the outliers before the prediction. For classification prediction problems, this algorithm is both simple and powerful.
4 classification and regression tree
Decision trees are also an important algorithm in predictive models. A two-forked tree can be used to represent the model of the decision tree. Each node represents an input, and each branch represents a variable (the default variable is a numeric type)

Decision tree
The leaf nodes of the decision tree refer to the output variables. The process of prediction will pass through the branch of the decision tree until it finally stops on a leaf node, corresponding to the classification result of the output value. The decision tree is very well learned and can quickly predict results. For most problems, the results are quite accurate and do not require preprocessing of the data.
5 naive Bayes classifier
This algorithm for predictive modeling is powerful enough to be beyond imagination. This model allows you to calculate the probability of two output categories directly from your training set. One is the probability of each type of output; the other is the conditional probability of the species based on the given value of x. Once calculated, the probabilistic model can predict new data using Bayes' theorem. When your data is real, then it is reasonable to say that it should be Gaussian, and it is easy to estimate this probability.
Bayes' theorem
The naive Bayesian theorem has a "simple" name because the algorithm assumes that each input variable is independent. However, real data cannot satisfy this hidden premise. Still, this method works well for many complex problems.
6K neighbor algorithm
The model representation of the nearest K nearest neighbor is the entire training set. Very straightforward, right? The prediction of the new data is to search the value of the entire training set and find the K most recent examples (literally neighbors). Then summarize the K output variables. This algorithm is difficult to define, how to define the similarity of two data (the distance is similar to the nearest one). If your attributes belong to the same scale, the easiest way is to use Euclidean distance. This value can be calculated based on the distance between each input variable.

The nearest neighbor method requires a large amount of memory space to put data, so that it can perform real-time operations (or learning) when it needs to be predicted. The training set can also be continually updated to make the predictions more accurate. The idea of ​​distance or intimacy encounters a higher dimension (a large number of input variables) that won't work, affecting the performance of the algorithm. This is called the curse of dimensions. When the (mathematical) spatial dimension increases, the high-dimensional space (usually hundreds of thousands of dimensions) is analyzed and organized, and various problem scenarios are encountered due to the increase in the volume index. So it's best to keep only those input variables that are related to the output value.
7 learning vector quantization
The downside of recent neighbors is that you need the entire training set. The neural network algorithm of learning vector quantization (hereinafter referred to as LVQ) is a self-selected training example.
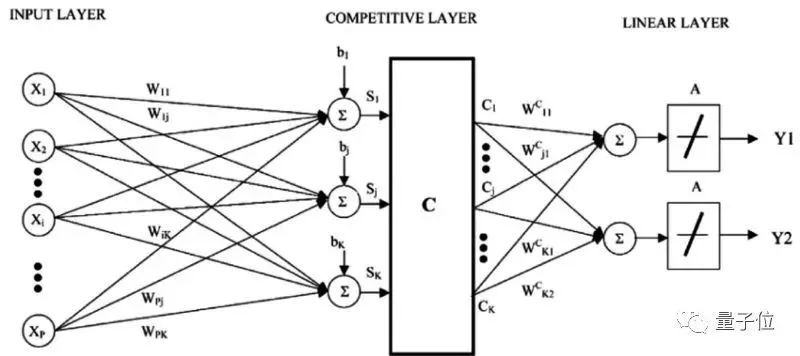
LVQ is a set of vectors, also called codebooks. Initially, the vectors are randomly selected. After several iterations of the learning algorithm, slowly select the vector that best represents the training set. After the study is completed, the codebook can be used to predict, just like the nearest neighbor. Calculate the distance between the new input sample and the codebook to find the closest neighbor, which is the best matching codebook. If you rescale the data and put the data in the same range, say 0 to 1, you can get the best results. If you get good results with the nearest neighbor method, you can use LVQ optimization to reduce the storage pressure of the training set.
8 support vector machine (referred to as SVM)
This is probably the most popular algorithm in machine learning. A hyperplane is a "line" of space that can divide an input variable. The hyperplane of the support vector machine is capable of cutting the input variable space as much as possible by type, either 0 or 1. In a two-dimensional space, you can divide the hyperplane into the "line" of the variable space. This line perfectly divides all input values ​​into two. The learning goal of SVM is to find out this hyperplane.
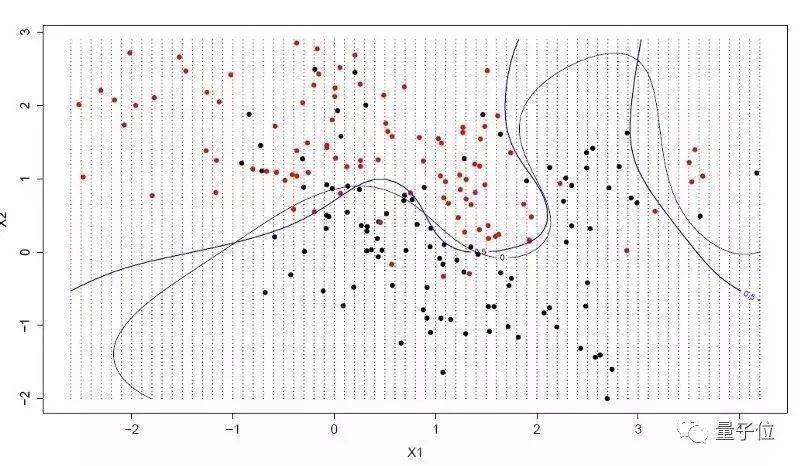
The distance between the hyperplane and the nearest data point is called the edge. The most ideal hyperplane is the ability to divide training data without errors. That is to say, the distance between the vector closest to the hyperplane and the hyperplane in each type of data reaches a maximum. These points are called support vectors and they define hyperplanes. In practice, the most ideal algorithm is to find these points that maximize the distance between the nearest vector and the hyperplane value. The support vector is probably the strongest classifier to use. It is worth trying with the data set.
9 random forest
Random forest, a repetitive sampling algorithm, is one of the most popular and powerful algorithms. In statistics, bootstrap is a very effective way to estimate the size. For example, estimate the average. Take some samples from the database, calculate the average, repeat this operation several times, and get multiple averages. Then average these averages and hope to get the closest real average. The bagging algorithm is to take multiple samples at a time and then model based on these samples. When predicting new data, the previously built models make predictions, and finally take the average of these predictions and try to approximate the true output value.
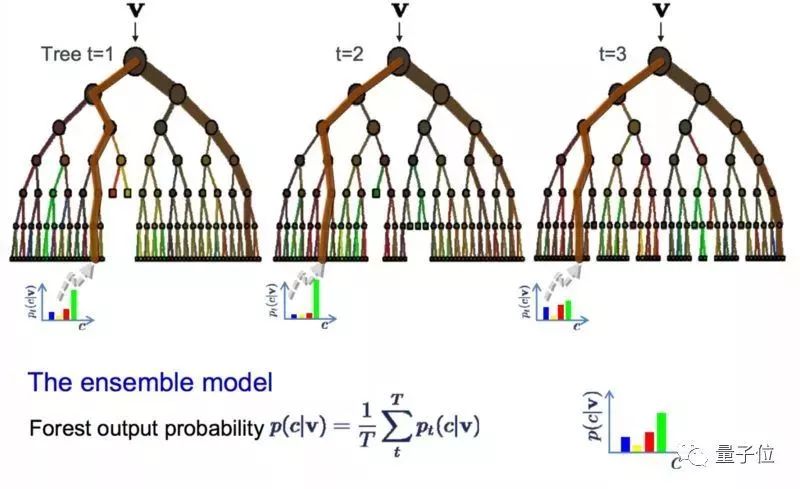
Random forests vary slightly on this basis. It contains a classifier for multiple decision trees, and the category of its output is determined by the mode of the category of the individual tree output. If your high-variance algorithm yields good results (say, decision trees), then using random forests will lead to better results.
10 Boosting algorithm and adaptive boost (Adaboost) algorithm
The core of Boosting is to train different classifiers (weak classifiers) on the same training set, and then combine these weak classifiers to form a stronger final classifier (strong classifier). The resulting second weak classifier corrects the error of the first weak classifier. Weak classifiers are constantly superimposed until the predictions are perfect. The Adaboost algorithm is the first lifting algorithm successfully used for binary classification problems. There are many enhancements now based on Adaboost.
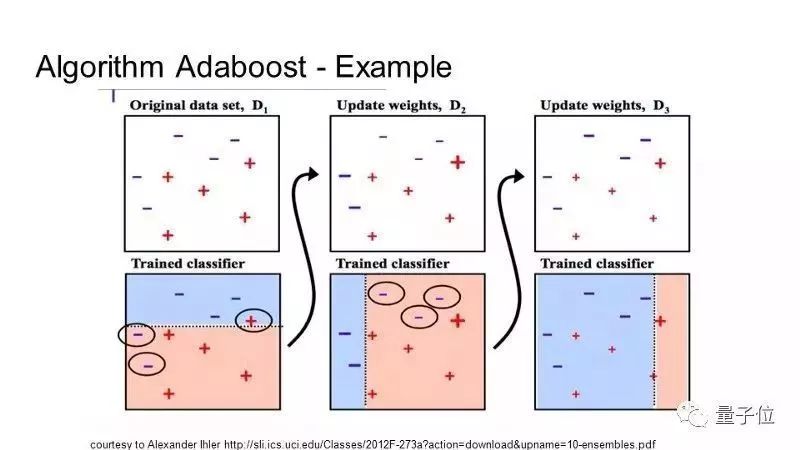
AdaBoost is suitable for short decision trees. After the first tree is built, the performance of different samples after training can be used as a reference. The weak classifiers are trained with different samples, and then the samples are weighted according to the error rate. Training data that is difficult to predict should give more weight, and conversely, better predictions will have less weight. The model is built one by one, and the weight of each training data is affected by the performance of the previous decision tree. When all the decision trees are built, look at the predicted performance of the new data, and the results are not accurate. Because the training data is very important for the correction algorithm, make sure the data is clean and there are no weird deviations.

Finally, in the end, facing the massive machine learning algorithm, Mengxin’s favorite question is, “What algorithm should I choose?†Before answering this question, I must first think clearly:
1) the quantity, quality and essence of the data;
2) the time available for calculation;
3) the urgency of this task;
4) What do you want to do with this data.
You know, even an old driver can't close his eyes and say which algorithm can get the best results. Still have to try. In fact, there are many algorithms for machine learning. The above is just a description of the types that are used more. It is more suitable for the new try to find the feeling.

AC wall 5V 2A power adapter with multiple tips works for many small 5V electronics. Like Scanner, Router, Bluetooth speaker, Foscam Wireless IP Camera, CCTV camera, USB hub, bluetooth GPS Receiver, tv box, tablets, Baby Monitor, Graco Swing, Home Phone System, VoIP Telephone Routers, Serato DJ Controller, DVR, ADSL Cat, External battery, hubs, switches, Led Strip, String Lights, vibrator, Raspberry pi 3 Raspberry Pi A/A+/B/B+ Raspberry Pi Zero and more 5V devices. (5V ONLY)
Worldwide Input: 110-240V; Output: 5V 1000mA, 1.5A, 1.75A, 5V 1A, 5V 500mA, 5V 2.1A, Max 10W. DC Tip Polarity: Central Positive(+). Please read manual carefully before using 5vdc power supply.
Design-safeguard features against incorrect voltage, short circuit, internal overheating and overloading. This 5v Ac power supply charger is made from quality material to ensure the long lifetime. Power your 5v electronics perfectly and replaces lots of 5 volt power chargers
Package include: 1 x High Quality 5V 2A AC DC Power Adapter, 1 Set x Tips
5V Switching wall charger 6V Switching wall charger 9V Switching wall charger 12V Switching wall charger 15V Switching wall charger 19V Switching wall charger 24V Switching wall charger 36V Switching wall charger 48V Switching wall charger
Shenzhen Waweis Technology Co., Ltd. , https://www.huaweishiadapter.com